PlantUML+GPT - Visual Studio Extension with AI Multi-Modality
Continuing my commitment to using the LLM (OpenAI/GPT) to help me draft diagrams in PlantUML, which started with the release of PlantUMLApp, led me to release a new update of the PlantUML+GPT Visual Studio Code Extension.
Multimodality
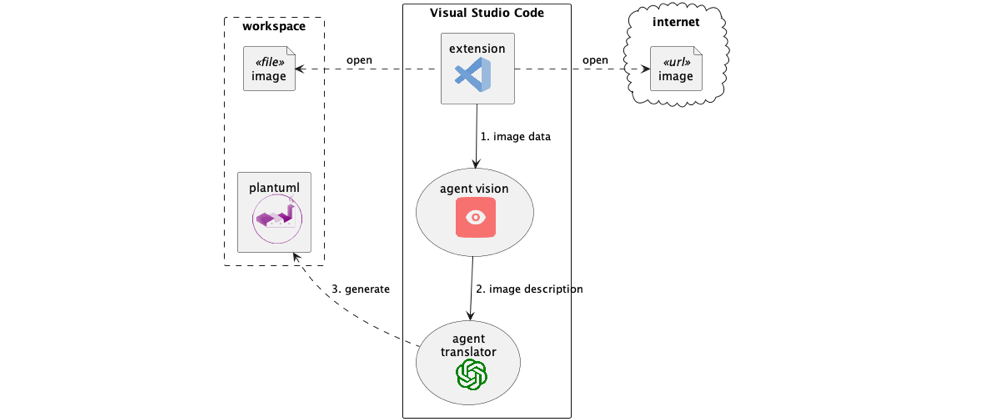
Version 0.4.x now includes the new multi-modality feature. This update allows you to use the Vision model to transform diagram images from the internet or your workspace into PlantUML scripts. Check out the animated GIF below.

The Multi Agents Collaboration
In this extension I’ve used Multi-Agents-Collaboration using the LangGraph framework from the awesome Langchain project, applying the process shown in the diagram below:
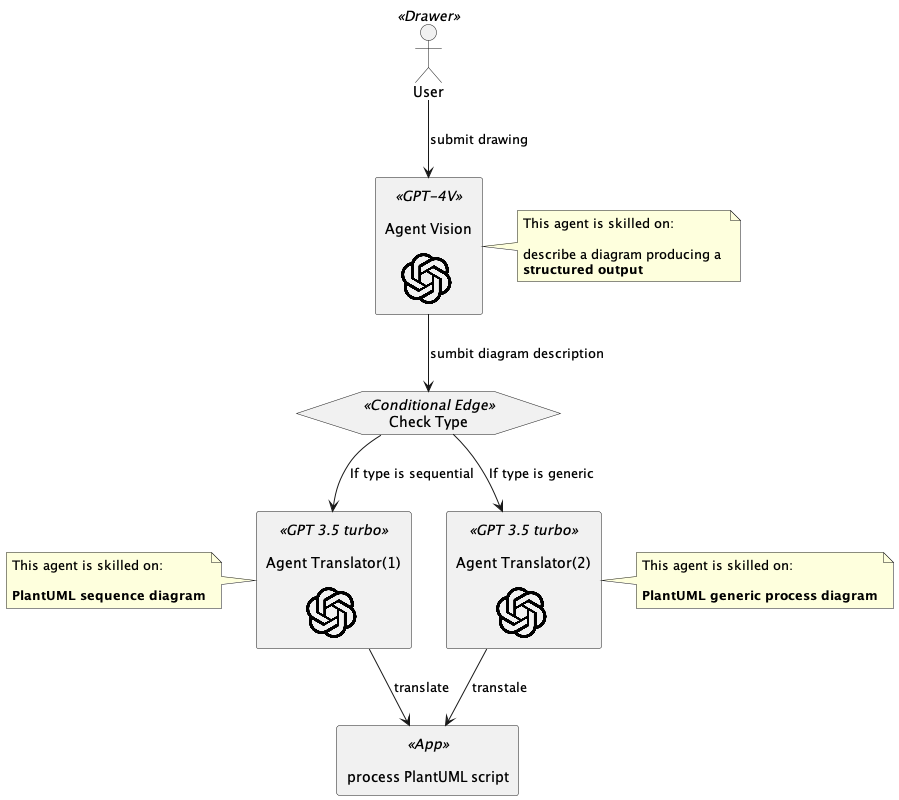
As you can see, I’ve used three Agents with different capabilities:
Agent Vision
This agent can process images, it is skilled in describing a diagram producing a structured output containing also the diagram typology useful to involve the right Agent for further processing.
This increase the flexibility of system because the image is translated in structured data that can be processed by agents with different skills and goals
Agent Translator(1)
This agent is skilled in PlantUML sequence diagram. It gets the diagram data and translate them in the PlantUML script
Agent Translator(2)
This agent is skilled in PlantUML generic process diagram. It gets the diagram data and translate them in PlantUML script
Conclusion
Multi-Modality enhances AI’s ability to understand various types of information encountered in daily life. Utilizing this capability can significantly boost the efficiency of your AI system. I am currently exploring this and plan to introduce an auto-correction process for errors, providing feedback to agents.
So, stay tuned! In the meanwhile, enjoy coding! 👋